
科学家在AI期间提出了数据层次保护治理计划,数
作者:365bet体育注册日期:2025/07/29 浏览:
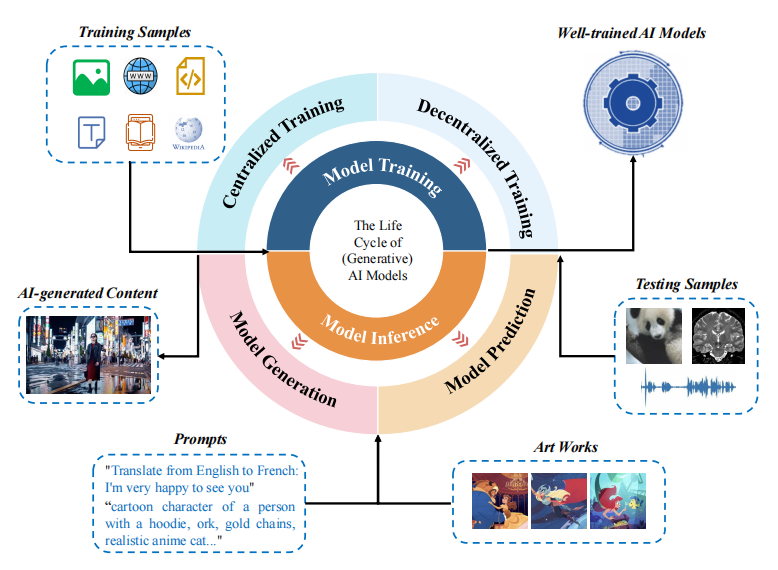 来源:在传统信息系统中,DeepTech通常在数据库或硬盘上存储数据,保护数据的方法相对简单 - “只需锁定”它。但是,随着生成人工智能(Genai)的快速发展,数据开始在许多链接中继续“流”,例如模型培训,扩展,呼叫和发电。这不再是静态资源,而是成为AI系统生命周期的积极参与者。数据流动性为其保护带来了新的挑战:我们不仅应该避免违反数据和滥用数据,而且还要确保在使用数据时,我们仍然保持“信息,控制,可追溯和删除”等基本权利。换句话说,在人工智能的开发过程中,数据保护不再等于TOA大小的所有“阻止”,而需要更详细且动态的管理计划。当然,基于这些观察结果,来自国家密钥的研究人员智格大学区块链和安全安全实验室以及新加坡南南技术大学等团队进行了一项联合研究,向读者解释了在以易于理解的语言开发人工智能期间,数据保护对数据保护的特定含义和遥远影响。这项工作系统地分类并回答了人工智能期间数据保护面临的一系列关键问题:应该保护哪些数据?应该采取哪些保护措施?可以遇到哪些新挑战?相关法规和法规情况的当前状态是什么?数据保护和数据安全性之间有哪些缺点差异和连接?研究小组进一步提出了一个分层数据治理框架,以试图在安全,存在和监管之间找到新的平衡。图丨在生成人工智能期间,数据不再是静态内容,而是围绕t流动他的整个生命周期。该图显示了如何生成不同的数据表格并在开发部署模型中收集的原始样本的新内容(来源:ARXIV)的过程中传播,应该理解,数据保护的传统概念是“以数据为中心的”,培训和保护都围绕数据本身旋转;该研究建议,在AI期间,数据保护本质上是“以模型为中心”,并且此类数据在AI模型中的pdevelopment,应用,联系,联系和制造过程中创造了价值。以该模型为主线,研究人员重新编写了可以暴露于整个生命周期的数据类型以及所涉及的所有链接,包括培训数据,训练有素的模型,系统提示单词,插入式知识库,用户输入和AI生成的数据等。这种创新的观点定义了未来AI技术健康和可持续发展的明确方向管理系统。该论文的第一本书是智格大学国家关键和数据安全国家关键实验室的特别研究人员,目前是新加坡南南技术大学(研究人员)的研究人员(研究人员)李·伊米宁博士对DeepTech博士:“我们的主要目标是在AI期间阐明了Pangudata保护和数据保护的全球范围,以阐明当前的数据,以阐明当前的数据,以宣传当前的一项基础,该量表的当前是一项旨在的,该量表是在当前的基础上宣传的。 “目前,相关论文已在标题为“重新考虑(生成)人工智能时期的数据保护”标题上发表在预印Arxiv网站[1]上。 Nanang Technological University是第一座,并且对应于Dr. Dr.下一个水平,其保护强度降低,并且数据实用程序随Naaathat的IT而上升。 1级,数据不可用:这是数据保护的最高级别,有必要确保特定数据不能用于培训或理解。例如,在以前的事件中,三星员工错误地将源代码传递给了chatgpt,他们可以使用“无法使用的数据”来保护它最初受到保护。第2级,隐私保护:基于保护私人信息,数据可用于模型开发和应用程序开发,即数据是“可用且不可见的”,该数据等于脱敏然后使用,从而降低了数据隐私泄漏的风险。实际上已经在以前的技术和相关法规中提出了此请求。 Li Yiming提供了一个例子:“例如,隐私的差异是在训练阶段注入噪音, - 流体研究在本地留下了原始音符,而仅上载梯度,而同型加密则可以直接操作云,以直接操作ciphertext。保护数据可以完全用于培训和理解的保护,这使用户可以通过“ AI形成期间的数据(来源:Arxiv)进行Kin事实,这是由于国家和地区对数据保护要求的显着差异,因此现有数据保护规定的范围可能存在空白。知道“”,以及中国的“生成人造人工智能服务”水印和徽标的个人信息保护。但是,这导致了跨国数据管理的问题:当前,培训大型模型的过程经常散布在世界各地。初创公司可以通过“移动位置”(例如,在易于培训的国家 /地区的训练数据中,都可以避免严格的法律障碍,然后避免使用易于培训的数据,并避免使用易于培训的数据。用宽松的模型管理和维修区域,然后将服务部署到无权删除权利的司法管辖区,以降低合规成本。表丨在生成工业智能时代(来源:ARXIV)对这种复杂情况的代表性数据保护法规,该研究表明,管理管理成功:当代数据保护的主要部分已从简单的“数据封锁”变为“控制价值”。这个概念可以反映在特定的应用情况下:AI医疗可能决定案件特征的模式,但并未揭示患者的隐私;法律AI可以参考数据库中案例的先前逻辑,但可能无法在数据库中输出完整的判断。实现这种平衡需要大量的技术支持,例如培训过程中隐私的隐私多样性,数字水印内容的流以及联邦研究的促进Ulti Party数据协作。特别是注意到这些技术解决方案达到了“数据保护”和“数据安全”的双重目标,这反映了两者的增加的增加:当模型可以防止攻击成员攻击成员时,不仅可以保护培训数据的隐私,还可以增强模型本身的安全性。图片丨li yiming(来源:李·伊米宁)李·伊明(Li Yiming)在Tsinghua University获得了计算机科学和技术博士学位,并成为了Zhejiang University Blockchain和数据安全的国家关键实验室的特别研究人员。目前,她是Nanyang Technological University的一项共同研究,以及她的研究方向,这些方向是可信赖的人工智能,尤其是AI的AI安全评论和AI版权保护。在论文讨论的一部分中,他和他的合作专门评估了“数据保护”和“数据安全”之间的相似性和差异。原则上,两个人e不同的担忧:前者着重于遵守模型的隐私和所涉及的数据,因为后者强调了模型本身和系统的稳定性。但是实际上,两者是密切相互关联的 - 数据保护不足可能导致系统不安全感,反之亦然。诸如联合学习,习惯隐私等技术已成为整个领域的单亲解决方案。正如研究提醒的那样,“数据保护与数据安全不同。”该分层框架的价值在于数据保护和管理的差异,因此该行业不必在“完全关闭”和“完全开放”之间进行选择,而是在不同情况和不同的法律领域(例如“批量”)之间找到了最佳平衡。 Li Yiming说:“我们认为,完整的数据管理计划将为更广泛的安全管理奠定坚实的基础。”参考材料:1.https:// arxiv。org/abs/2507.03034操作/类型:他钦隆
来源:在传统信息系统中,DeepTech通常在数据库或硬盘上存储数据,保护数据的方法相对简单 - “只需锁定”它。但是,随着生成人工智能(Genai)的快速发展,数据开始在许多链接中继续“流”,例如模型培训,扩展,呼叫和发电。这不再是静态资源,而是成为AI系统生命周期的积极参与者。数据流动性为其保护带来了新的挑战:我们不仅应该避免违反数据和滥用数据,而且还要确保在使用数据时,我们仍然保持“信息,控制,可追溯和删除”等基本权利。换句话说,在人工智能的开发过程中,数据保护不再等于TOA大小的所有“阻止”,而需要更详细且动态的管理计划。当然,基于这些观察结果,来自国家密钥的研究人员智格大学区块链和安全安全实验室以及新加坡南南技术大学等团队进行了一项联合研究,向读者解释了在以易于理解的语言开发人工智能期间,数据保护对数据保护的特定含义和遥远影响。这项工作系统地分类并回答了人工智能期间数据保护面临的一系列关键问题:应该保护哪些数据?应该采取哪些保护措施?可以遇到哪些新挑战?相关法规和法规情况的当前状态是什么?数据保护和数据安全性之间有哪些缺点差异和连接?研究小组进一步提出了一个分层数据治理框架,以试图在安全,存在和监管之间找到新的平衡。图丨在生成人工智能期间,数据不再是静态内容,而是围绕t流动他的整个生命周期。该图显示了如何生成不同的数据表格并在开发部署模型中收集的原始样本的新内容(来源:ARXIV)的过程中传播,应该理解,数据保护的传统概念是“以数据为中心的”,培训和保护都围绕数据本身旋转;该研究建议,在AI期间,数据保护本质上是“以模型为中心”,并且此类数据在AI模型中的pdevelopment,应用,联系,联系和制造过程中创造了价值。以该模型为主线,研究人员重新编写了可以暴露于整个生命周期的数据类型以及所涉及的所有链接,包括培训数据,训练有素的模型,系统提示单词,插入式知识库,用户输入和AI生成的数据等。这种创新的观点定义了未来AI技术健康和可持续发展的明确方向管理系统。该论文的第一本书是智格大学国家关键和数据安全国家关键实验室的特别研究人员,目前是新加坡南南技术大学(研究人员)的研究人员(研究人员)李·伊米宁博士对DeepTech博士:“我们的主要目标是在AI期间阐明了Pangudata保护和数据保护的全球范围,以阐明当前的数据,以阐明当前的数据,以宣传当前的一项基础,该量表的当前是一项旨在的,该量表是在当前的基础上宣传的。 “目前,相关论文已在标题为“重新考虑(生成)人工智能时期的数据保护”标题上发表在预印Arxiv网站[1]上。 Nanang Technological University是第一座,并且对应于Dr. Dr.下一个水平,其保护强度降低,并且数据实用程序随Naaathat的IT而上升。 1级,数据不可用:这是数据保护的最高级别,有必要确保特定数据不能用于培训或理解。例如,在以前的事件中,三星员工错误地将源代码传递给了chatgpt,他们可以使用“无法使用的数据”来保护它最初受到保护。第2级,隐私保护:基于保护私人信息,数据可用于模型开发和应用程序开发,即数据是“可用且不可见的”,该数据等于脱敏然后使用,从而降低了数据隐私泄漏的风险。实际上已经在以前的技术和相关法规中提出了此请求。 Li Yiming提供了一个例子:“例如,隐私的差异是在训练阶段注入噪音, - 流体研究在本地留下了原始音符,而仅上载梯度,而同型加密则可以直接操作云,以直接操作ciphertext。保护数据可以完全用于培训和理解的保护,这使用户可以通过“ AI形成期间的数据(来源:Arxiv)进行Kin事实,这是由于国家和地区对数据保护要求的显着差异,因此现有数据保护规定的范围可能存在空白。知道“”,以及中国的“生成人造人工智能服务”水印和徽标的个人信息保护。但是,这导致了跨国数据管理的问题:当前,培训大型模型的过程经常散布在世界各地。初创公司可以通过“移动位置”(例如,在易于培训的国家 /地区的训练数据中,都可以避免严格的法律障碍,然后避免使用易于培训的数据,并避免使用易于培训的数据。用宽松的模型管理和维修区域,然后将服务部署到无权删除权利的司法管辖区,以降低合规成本。表丨在生成工业智能时代(来源:ARXIV)对这种复杂情况的代表性数据保护法规,该研究表明,管理管理成功:当代数据保护的主要部分已从简单的“数据封锁”变为“控制价值”。这个概念可以反映在特定的应用情况下:AI医疗可能决定案件特征的模式,但并未揭示患者的隐私;法律AI可以参考数据库中案例的先前逻辑,但可能无法在数据库中输出完整的判断。实现这种平衡需要大量的技术支持,例如培训过程中隐私的隐私多样性,数字水印内容的流以及联邦研究的促进Ulti Party数据协作。特别是注意到这些技术解决方案达到了“数据保护”和“数据安全”的双重目标,这反映了两者的增加的增加:当模型可以防止攻击成员攻击成员时,不仅可以保护培训数据的隐私,还可以增强模型本身的安全性。图片丨li yiming(来源:李·伊米宁)李·伊明(Li Yiming)在Tsinghua University获得了计算机科学和技术博士学位,并成为了Zhejiang University Blockchain和数据安全的国家关键实验室的特别研究人员。目前,她是Nanyang Technological University的一项共同研究,以及她的研究方向,这些方向是可信赖的人工智能,尤其是AI的AI安全评论和AI版权保护。在论文讨论的一部分中,他和他的合作专门评估了“数据保护”和“数据安全”之间的相似性和差异。原则上,两个人e不同的担忧:前者着重于遵守模型的隐私和所涉及的数据,因为后者强调了模型本身和系统的稳定性。但是实际上,两者是密切相互关联的 - 数据保护不足可能导致系统不安全感,反之亦然。诸如联合学习,习惯隐私等技术已成为整个领域的单亲解决方案。正如研究提醒的那样,“数据保护与数据安全不同。”该分层框架的价值在于数据保护和管理的差异,因此该行业不必在“完全关闭”和“完全开放”之间进行选择,而是在不同情况和不同的法律领域(例如“批量”)之间找到了最佳平衡。 Li Yiming说:“我们认为,完整的数据管理计划将为更广泛的安全管理奠定坚实的基础。”参考材料:1.https:// arxiv。org/abs/2507.03034操作/类型:他钦隆 上一篇:哪种悬念游戏很有趣?很难玩悬念游戏的十大游
下一篇:没有了
下一篇:没有了
相关文章
- 2025/07/29朱利安·莱费伊(Julian Lefay),卷轴上古
- 2025/07/28独家的!今年前四个月,政府的规模和商
- 2025/07/28独家:重庆电信从内部推广了一位新的副
- 2025/07/27三星错过了AI的机会! 2018年,黄伦Xun主动
- 2025/07/27毁灭4GHz后将发射焦点9500

 客户经理
客户经理